


.png)
%20(1).png)
.png)





.svg)
.svg)
.svg)

.png)
.png)
.png)
.svg)
.svg)
%20(1).png)
.svg)
.png)


.png)
.svg)
.svg)
.svg)

%20(1).png)
.png)
.png)

.png)
.png)
.svg)
.svg)
%20(1).png)
%20(1).png)
.png)



SocialPilot Alternatives forAgencies:Where Its Ceiling Is, and Whatto Switch To
Key Takeaway: Autonomous crisis detection uses AI to monitor brand mentions, sentiment shifts, and engagement velocity across social media, review platforms, news sites, and forums in real time. Brands using velocity-based alerting identify high-risk incidents 3 to 4 hours faster than those relying on keyword monitoring alone — often the difference between a quiet fix and a national PR crisis.
What You'll Learn in This Guide
- Why traditional brand monitoring fails during real crises
- The 4-hour reputation spiral and how to break it
- How velocity-based detection outperforms keyword-based monitoring
- A step-by-step crisis shield workflow for multi-location brands
- Platform comparison and implementation playbook
What Is Autonomous Crisis Detection?
Autonomous crisis detection is an AI-powered monitoring system that continuously scans social media platforms, review sites, news outlets, forums, and other digital channels for early indicators of brand reputation risk — and alerts the appropriate team members automatically, without requiring a human to be actively watching a dashboard.
The word "autonomous" is the critical distinction. Traditional social listening tools require someone to check a dashboard, review flagged mentions, and manually assess severity. Autonomous systems operate continuously, evaluate risk severity using AI, and push alerts to specific team members via SMS, Slack, email, or mobile notification the moment a threshold is crossed. The monitoring never sleeps, even when your team does.
For multi-location brands and franchise networks, this capability is not optional. A single franchise location can generate a reputation incident at any hour, on any platform, in any market. According to Sprout Social's 2025 Crisis Management Report, 68% of brand crises that went viral originated outside of business hours, and 41% started on platforms or channels the brand was not actively monitoring. This is why brand monitoring automation has become a non-negotiable capability for multi-location brands.
The fundamental problem autonomous detection solves is time. In crisis communications, the response window between "containable incident" and "viral reputation damage" has compressed from days to hours. A 2024 study by the Institute for Public Relations found that brands that respond to a crisis within the first 60 minutes experience 70% less negative sentiment amplification than those that respond after four hours. Autonomous detection is the infrastructure that makes a 60-minute response possible at scale.
Related reading: Predictive Sentiment Analytics: How to Predict Customer Churn Before It Happens · Unified Inbox ROI for 100+ Franchises
The 4-Hour Reputation Spiral: Anatomy of a Brand Crisis
Most brand crises do not begin with a press conference or a lawsuit. They begin with a single post on a platform nobody on your team is watching. Here is the pattern, reconstructed from real incident data across franchise networks managed through Eclincher.
The Timeline
Sunday, 11:22 PM — A customer posts a 45-second video of a hygiene issue at a franchise location to a niche local Facebook group with 8,000 members. They do not tag the brand. They do not use the brand name as a hashtag. They say "guess where this was" and tag the neighborhood.
Monday, 2:15 AM — A member of the Facebook group cross-posts the video to a regional subreddit. It gains 200 upvotes and 40 comments in three hours. Several commenters name the brand and the specific location. A local news reporter who monitors the subreddit bookmarks the thread.
Monday, 6:45 AM — An influencer with 85,000 followers sees the Reddit thread, screen-records the video, and reposts it to X (formerly Twitter) with the caption "This is why I stopped eating at [Brand]." The post gains 1,200 impressions in the first 30 minutes.
Monday, 8:30 AM — Your marketing director opens their laptop. Their phone is already ringing. The CEO is asking for a statement. The local news station has sent a request for comment. You are four hours behind the narrative — and every minute of delay compounds the damage.
Why This Pattern Repeats
This spiral is not unusual. It is the default trajectory of an undetected brand incident in 2026. The pattern repeats because of three structural factors:
Cross-platform migration. Incidents rarely stay on the platform where they originate. A Facebook post becomes a Reddit thread becomes a Twitter/X viral moment. Traditional monitoring tools that only watch your brand's owned channels miss the first two stages entirely.
Off-hours timing. The most damaging incidents disproportionately occur outside business hours — evenings, weekends, and holidays — when social teams are offline. Manual monitoring has a structural blindspot during the exact hours when response speed matters most.
Untagged mentions. Customers experiencing a negative event often do not tag the brand directly. They post to local groups, neighborhood forums, and niche communities where they expect sympathy, not corporate attention. Keyword-only monitoring misses these conversations entirely because the brand name never appears.
Key insight: A crisis does not always start with your brand name. It often starts with a location, a product, or a disgruntled employee's post. If your monitoring is limited to brand-name keywords, you are not watching the fuse — you are waiting for the explosion.
(Recommended visual: Create a horizontal timeline infographic showing the 4-hour spiral from initial post to CEO phone call, with detection windows marked at each stage.)
Why Keyword Monitoring Fails: Volume vs. Velocity in Crisis Detection
The most important insight in modern crisis monitoring is the distinction between mention volume and mention velocity. Most social listening tools are built to report volume — how many times was your brand mentioned today? Autonomous crisis detection systems are built to detect velocity — how fast is a specific conversation accelerating?
The Problem with Volume-Based Monitoring
A brand with 100+ franchise locations might generate 500 to 2,000 social mentions per day under normal conditions. Review responses, customer questions, tagged photos, loyalty program mentions, and routine engagement create a steady baseline of activity. Volume-based monitoring reports this aggregate number and flags when it exceeds a threshold — say, 20% above the daily average.
The problem: a crisis originating at a single location might add only 30 to 50 mentions in its first two hours. Against a baseline of 1,500 daily mentions, that increase is statistically invisible to a volume-based system. By the time the volume spike is large enough to trigger an alert — perhaps 300+ additional mentions — the incident has already migrated across platforms and may be trending regionally.
How Velocity-Based Detection Works
Velocity-based detection does not measure how many mentions you have. It measures how fast mention clusters are growing in a specific context.
The system monitors three velocity signals:
Geographic acceleration. Five mentions of your brand and a specific city name within 30 minutes, when the baseline for that city is two mentions per day. The absolute number is tiny. The rate of change is enormous.
Authority acceleration. A mention by a single account with 50,000+ followers, or by a verified journalist, or on a news site — even if it is only one mention. Volume-based systems would ignore a single mention. Velocity systems weight it by the potential reach and authority of the source.
Sentiment acceleration. A cluster of mentions where the average sentiment score drops below -0.6 within a 60-minute window, even if the cluster is only 10 to 15 messages. The speed of sentiment decline matters more than the number of negative messages.
Key insight: 1,000 bot accounts mentioning your brand is noise. Five high-authority local accounts mentioning a "safety concern" at one of your locations is a potential crisis. If your monitoring tool cannot distinguish between these two scenarios, it is just an expensive alarm clock.
What the Research Shows
According to Cision's 2025 State of the Media Report, the median time between a local incident and regional media pickup has decreased from 18 hours in 2020 to 4.2 hours in 2025. For brands in regulated industries (food service, healthcare, childcare), the window is even shorter — averaging 2.8 hours. This compression makes velocity-based detection a structural requirement, not a nice-to-have feature. Understanding what social media listening is and why it matters is the first step toward building this capability.
The Crisis Shield Workflow: A 3-Step Framework
The following workflow operationalizes autonomous crisis detection for multi-location brands. It is designed to run continuously without human monitoring, escalating only when intervention is required.
(Recommended visual: Create a workflow diagram showing Capture → Categorize → Calibrate with key actions and alert paths at each stage.)
Step 1: Capture
The AI agent continuously monitors social media APIs, review platforms (Google Business Profile, Yelp, TripAdvisor), news aggregators, Reddit, local Facebook groups, and industry-specific forums. It scans for two categories of signals:
Direct signals — mentions of the brand name, location names, product names, executive names, and branded hashtags across all monitored channels.
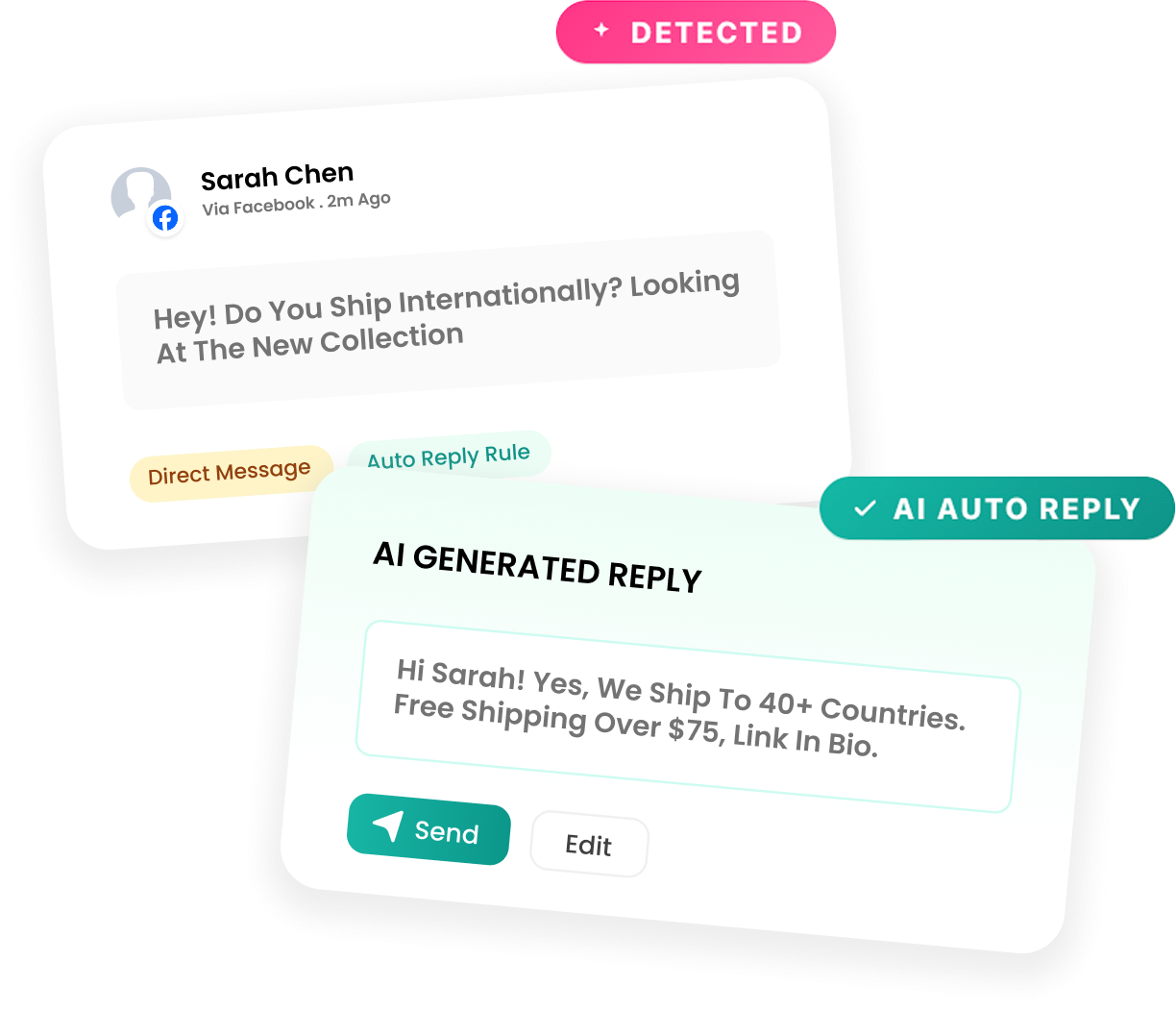
Contextual signals — semantic clusters related to risk categories (health and safety language, legal terminology, employment disputes, product defect descriptions) that appear in geographic proximity to a brand location, even when the brand is not explicitly named. This is the capability that catches the "untagged" mentions that start most crisis spirals.
Technical requirement: The capture layer must process mentions in near-real-time (under 5-minute latency) and must cover platforms where the brand does not have an owned presence. Monitoring only your own Facebook page and Instagram account is not crisis detection — it is inbox management.
Step 2: Categorize
Incoming signals are evaluated against a Sentiment Gravity matrix that separates routine negativity from genuine crisis indicators. The system classifies each signal cluster into one of four severity tiers:
Tier 1 — Routine negativity. Individual customer complaints, one-star reviews, negative comments on posts. These are normal operational noise. They require standard response workflows but do not warrant crisis escalation. Approximately 92% to 95% of negative mentions fall into this tier.
Tier 2 — Elevated concern. A cluster of 3 or more negative mentions about the same location or issue within a 2-hour window, or a single mention from a high-authority source (journalist, influencer, elected official). These warrant immediate review by the regional manager but do not yet require corporate crisis response.
Tier 3 — Active threat. Velocity acceleration detected: mention frequency for a specific location or issue is growing at 3x or more above baseline, cross-platform migration is occurring, or a media outlet has published or is preparing coverage. Corporate communications team is alerted immediately.
Tier 4 — Crisis in progress. The incident is trending regionally or nationally. Media coverage is live. The brand is being named in high-engagement social threads. This requires full crisis protocol activation: executive briefing, prepared statements, coordinated response across all channels.
The categorization is not static. The system continuously re-evaluates severity as new signals arrive. A Tier 2 incident that shows velocity acceleration is automatically upgraded to Tier 3 without requiring a human to reclassify it.
Step 3: Calibrate
Based on the severity tier, the system triggers the appropriate alert and response workflow:
For Tier 2 and above, the system provides a context package with the alert: the originating post(s), the current spread map (which platforms, which accounts), the sentiment trajectory, and a suggested initial response based on the brand's pre-approved crisis playbook.
Key insight: The suggested response is a starting point, not an autopilot. Autonomous detection means the system identifies and escalates without human monitoring. Autonomous response — letting AI post crisis statements without human review — is a risk that most brands should not take. The goal is to compress detection time to near-zero, giving human communicators the maximum possible window to craft an appropriate response.
Crisis Detection at Scale: Single Location vs. 100+ Franchises
Single-Location Brand
For a single-location business, crisis detection is primarily about speed and coverage. The owner or marketing manager needs to know within minutes — not hours — when a negative post gains traction, and they need visibility beyond just their owned social profiles.
A well-configured Google Alerts setup combined with a social inbox tool that covers reviews and DMs provides baseline crisis visibility for a single location. The risk surface is small enough that manual review of daily alerts is feasible.
Multi-Location Franchise (25 to 500+ Locations)
The crisis detection challenge scales non-linearly with location count. Each additional location adds not just another profile to monitor, but another geographic market, another set of local community groups, another pool of employees who might post, and another physical site where an incident can occur.
A 100-location franchise has 100 potential crisis origination points, each operating in a different local context with different local media, different community dynamics, and different risk profiles. A food safety issue at a location in a college town will spread differently than the same issue at a location in a retirement community.
At this scale, the critical capabilities are:
Location-level alert routing. When a Tier 2 or Tier 3 signal fires, it must reach the specific regional manager responsible for that location — not a generic corporate inbox. A crisis alert about the Denver location is useless if it goes to the regional manager responsible for Atlanta.
Cross-location pattern detection. A single customer complaint at one location is Tier 1. The same complaint type appearing at three locations in the same region within the same week might indicate a systemic issue (supply chain problem, policy failure, training gap) that warrants corporate investigation even before any individual location reaches Tier 2.
Franchise owner visibility controls. Local franchise owners need to see alerts relevant to their location. They should not see alerts for other locations, and they should not have the ability to respond to Tier 3 or Tier 4 incidents without corporate coordination. Permission controls are not a nice-to-have at franchise scale — they are a crisis management necessity.
How to Calculate the Cost of a Missed Crisis
Crisis detection is often treated as insurance — a cost that is hard to justify until the incident happens. The following framework provides a model for quantifying the financial exposure that autonomous detection mitigates.
The Direct Cost Model
Revenue impact per incident: Research published in the Journal of Marketing has shown that a single viral negative incident can depress store-level revenue by 10% to 30% in the affected market for 4 to 12 weeks. For a franchise location generating $80,000 per month in revenue, a moderate incident (15% revenue decline for 8 weeks) represents approximately $24,000 in lost revenue at that single location. Brands that invest in reputation management reduce this exposure significantly.
Regional contagion: Viral incidents rarely stay contained to the originating location. Consumer research from BrightLocal's 2025 Local Consumer Review Survey found that 67% of consumers generalize a negative experience at one franchise location to the broader brand. A crisis at one location can depress traffic at neighboring locations by 5% to 10% for several weeks.
Recovery cost: Crisis recovery involves paid media to rebuild brand perception, potential legal costs, PR agency fees for brands that do not have in-house crisis communications, and the opportunity cost of the executive and marketing team hours consumed by the response. A 2024 PwC Global Crisis Survey found that the median total cost of a brand crisis for mid-market companies was $4.2 million when accounting for all direct and indirect expenses.
The Detection ROI Formula
Crisis Cost Avoided = (Incidents Detected Early × Average Incident Cost × Containment Rate) − Platform Cost
For a 100-location franchise:
The wide range reflects the inherent variance of crisis events. Some years a brand may experience zero Tier 3+ incidents. Others may face several. The relevant comparison is not "what did the platform save us this quarter?" but "what is the expected annual cost of operating without real-time detection?" Insurance is not evaluated by whether you filed a claim this month.
Platform Comparison: Crisis Detection and Brand Monitoring Tools in 2026
The crisis detection market includes social-first tools with monitoring capabilities, dedicated media intelligence platforms, and enterprise reputation management suites. The following comparison evaluates the most commonly considered options for multi-location brands as of March 2026.
Methodology note: This comparison reflects publicly documented capabilities as of March 2026. Feature availability varies by plan tier and contract terms. Brandwatch and Meltwater are dedicated media intelligence platforms with deeper news and journalist coverage than social-first tools; their inclusion reflects the reality that crisis detection often requires monitoring beyond social media. We recommend requesting live demonstrations using your own multi-location data and a simulated crisis scenario to evaluate response time and alert quality.
Building a Crisis Response Playbook for Multi-Location Brands
Autonomous detection is only valuable if the organization knows what to do when an alert fires. The detection system compresses the timeline; the playbook determines the quality of the response.
Pre-Crisis Preparation
Stakeholder map. Document exactly who needs to be notified at each severity tier, with primary and backup contacts. Include phone numbers, not just email addresses — Tier 3 and Tier 4 events require voice communication.
Pre-approved response templates. Draft holding statements for the five most likely crisis categories for your industry. For food service: hygiene incident, foodborne illness report, employee conduct, facility damage, supply chain disruption. For healthcare: patient safety concern, data breach, regulatory finding, staff misconduct, facility issue. These templates should be approved by legal and executive leadership before a crisis occurs — not during one.
Escalation authority matrix. Define who has authority to post public responses at each tier. Tier 1: local franchise owner or community manager. Tier 2: regional manager with corporate template. Tier 3 and above: corporate communications only, with executive sign-off. This matrix must be documented, trained, and enforced. A franchise owner responding independently to a Tier 3 event can transform a containable incident into a full crisis.
Simulation schedule. Run a tabletop crisis simulation at least twice per year. Use the autonomous detection system to generate a simulated alert and walk the team through the response workflow in real time. The first time a regional manager receives a Tier 3 SMS alert should not be during an actual crisis.
During-Crisis Protocol
First 15 minutes: Acknowledge the alert internally. Confirm the facts — is the reported incident real? Activate the stakeholder notification chain for the appropriate tier. Do not post publicly until facts are confirmed.
First 60 minutes: Issue a holding statement if the incident is public and gaining velocity. The statement should acknowledge awareness, express concern, and commit to investigation. It should not speculate on cause, assign blame, or make promises. Coordinate with the local franchise owner to ensure they are not responding independently.
First 4 hours: Provide a substantive update. By this point, initial facts should be available. Communicate what is known, what actions have been taken, and when the next update will be provided. Monitor sentiment velocity to assess whether the response is reducing or amplifying the conversation.
Post-crisis (24 to 72 hours): Conduct a detailed after-action review. Document the detection timeline: when did the incident occur, when was it detected, when was the first alert sent, when was the first response posted? Identify gaps and update the playbook, alert thresholds, and training accordingly.
Implementation Guide: From Pilot to Network-Wide Coverage
Phase 1: Risk Audit and Baseline (Weeks 1 to 3)
Before deploying autonomous detection, conduct a risk audit of your current monitoring coverage. Document which platforms and channels are actively monitored, what the average detection time is for negative mentions (measure this by reviewing recent incidents), and which locations or markets have the weakest coverage. Also document your current response workflow: who receives alerts, how are they routed, and what is the typical time from detection to first response?
Phase 2: Pilot Deployment (Weeks 4 to 8)
Select 10 to 15 locations across at least 2 regions. Choose locations with different risk profiles — include urban and suburban, high-volume and moderate-volume, and at least one location with a history of negative incidents. Connect all social profiles, review platforms, and local community monitoring to the detection system.
During the pilot, run in "shadow mode" for the first two weeks: let the system generate alerts without sending them to regional managers. Review the alerts internally to calibrate severity thresholds and reduce false positives before exposing the field team to notifications.
Phase 3: Threshold Calibration (Weeks 6 to 10)
Adjust velocity thresholds based on pilot data. Each market has a different baseline mention rate, and thresholds that are appropriate for a high-volume urban location will generate false positives in a quieter suburban market. The calibration goal is a false positive rate below 15% for Tier 2+ alerts — high enough to avoid missing genuine threats, low enough to maintain team trust in the system.
Phase 4: Regional Rollout (Weeks 11 to 18)
Expand one region at a time. Train regional managers on the alert system, severity tiers, and response protocols before their region goes live. Run at least one simulated Tier 2 or Tier 3 alert during training so that each manager experiences the workflow before a real incident occurs.
Phase 5: Full Network and Continuous Optimization (Week 19+)
Complete deployment across all locations. Establish monthly reviews of alert data: how many alerts per tier, average response time, false positive rate, and any incidents that were missed or misclassified. Quarterly, update the crisis playbook based on new incident types, platform changes, and lessons learned.
Common Mistakes That Leave Brands Exposed
Mistake 1: Monitoring Only Owned Channels
If your crisis detection only covers your brand's Facebook page, Instagram account, and Google reviews, you are monitoring the destination, not the origin. Most crises start in spaces you do not own — local community groups, Reddit, employee forums, niche review sites, and private messaging that eventually leaks to public platforms. Detection must extend beyond owned channels.
Mistake 2: Setting Volume Thresholds Instead of Velocity Thresholds
A 20% increase in daily mention volume is a volume threshold. Five high-authority mentions in a single geographic market within 30 minutes is a velocity threshold. Volume thresholds catch crises after they have already scaled. Velocity thresholds catch them during the critical early window when containment is still possible.
Mistake 3: No After-Hours Coverage
If your detection system sends alerts to a dashboard that nobody checks between 6 PM and 8 AM, you have a logging system, not a detection system. Autonomous crisis detection must include push notifications via SMS or phone call for Tier 2+ events regardless of time of day. The 4-hour spiral in Section 2 started at 11:22 PM on a Sunday. Your detection system must be operational when your team is not.
Mistake 4: Letting Local Franchisees Respond to High-Severity Incidents
A franchise owner who sees negative coverage of their location and fires off a defensive response on social media can escalate a Tier 2 event to a Tier 4 crisis in a single post. Permission controls must prevent local operators from posting public responses to Tier 3+ events. Corporate communications handles the narrative; the franchisee handles the operational fix.
Mistake 5: Treating Crisis Detection as a One-Time Setup
Platform dynamics change. New social networks emerge (Threads, Bluesky). Existing platforms change their API access. Community groups migrate. Crisis detection coverage must be reviewed quarterly and updated to reflect the current landscape of where conversations about your brand are actually happening — not where they were happening when you set up the system.
How Eclincher Enables Autonomous Crisis Detection at Scale
Eclincher's crisis detection capabilities are built for the specific operational reality of multi-location brands and franchise networks.
Velocity-based alerting. Eclincher monitors geographic, authority, and sentiment velocity — not just mention volume. A cluster of high-authority mentions in a single market triggers an alert even if the absolute mention count is low. This is the capability that catches crises in the first 30 minutes, not the first 4 hours.
Location-level routing with franchise hierarchy. Alerts are routed to the specific regional manager responsible for the affected location, with automatic escalation to corporate communications when severity thresholds are crossed. The permission structure ensures that local franchise owners see what is relevant to their location while corporate retains control of crisis-level responses.
AI-drafted response suggestions. For Tier 2 and Tier 3 alerts, the system provides a suggested initial response based on the brand's pre-configured crisis playbook and the specific context of the incident. This is designed to reduce the response drafting time from 30+ minutes to under 5, helping teams meet the 15-minute response target for active threats.
Where Eclincher is not the right fit: Brands that require deep news and print media monitoring as their primary crisis detection channel should evaluate dedicated media intelligence platforms like Meltwater or Brandwatch. Eclincher's strength is in social, review, and community-level detection — the channels where most franchise-level crises originate — not in monitoring national print media or broadcast news.
Explore Eclincher's crisis detection capabilities →
Frequently Asked Questions
What is autonomous crisis detection?
Autonomous crisis detection is an AI-powered system that continuously monitors social media, review platforms, news sites, and forums for early indicators of brand reputation risk. Unlike traditional social listening tools that require a human to check a dashboard, autonomous systems evaluate risk severity using AI and push alerts to the appropriate team members automatically via SMS, Slack, or phone call the moment a threshold is crossed.
How is autonomous crisis detection different from social listening?
Social listening monitors what people are saying about your brand. Autonomous crisis detection monitors how fast conversations are escalating and whether they represent a genuine threat. Social listening reports on volume and sentiment after the fact. Crisis detection identifies velocity changes and authority signals in real time and triggers proactive alerts before an incident goes viral.
How fast can AI detect a brand crisis?
Modern autonomous detection systems can identify a crisis signal within 5 to 15 minutes of the originating post, depending on the platform and the detection method. The practical constraint is not AI speed — it is platform API latency and the coverage breadth of the monitoring system. Brands using velocity-based detection typically identify Tier 2+ incidents 3 to 4 hours faster than those relying on keyword monitoring or manual dashboard review.
What is velocity-based monitoring?
Velocity-based monitoring measures how fast a conversation is accelerating rather than how many mentions your brand has received. It tracks three velocity dimensions: geographic acceleration (mentions clustering in a specific market), authority acceleration (mentions from high-reach or high-credibility sources), and sentiment acceleration (rapid sentiment decline within a short window). This approach catches crises during the early containment window that volume-based monitoring misses.
How much does autonomous crisis detection cost for a franchise?
Enterprise-grade crisis detection platforms for 100+ location franchise networks typically range from $2,000 to $10,000 per month, depending on the number of monitored locations, platform coverage, and alerting sophistication. When compared to the median cost of a single uncontained brand crisis ($50,000 to $4.2 million depending on severity), the ROI is substantial even if the system prevents only one escalation per year.
Can autonomous detection prevent a crisis entirely?
It cannot prevent the originating incident — a hygiene issue, a customer service failure, or an employee conduct problem will still occur. What it can do is compress the detection-to-response time from hours to minutes, allowing the brand to contain the narrative before cross-platform amplification occurs. Data consistently shows that crises responded to within the first 60 minutes produce 70% less negative sentiment amplification than those responded to after four hours.
What platforms should crisis detection cover for a franchise brand?
At minimum: Facebook (pages and groups), Instagram, X (formerly Twitter), Google Business Profile, Yelp, TripAdvisor (for hospitality), Reddit, and local news sites. Many franchise crises originate in local Facebook community groups where the brand is not tagged, making contextual/semantic monitoring (not just keyword matching) essential. The specific platform mix should reflect where your customers and local communities actually have conversations — not just where your brand has a profile.
How do you reduce false positives in crisis detection?
The primary lever is threshold calibration. Set velocity thresholds based on location-specific baselines rather than network-wide averages, since mention patterns vary significantly between high-traffic urban locations and quieter suburban ones. Review false positive rates monthly and adjust. The target is a false positive rate below 15% for Tier 2+ alerts — low enough to maintain team trust, high enough to avoid missing genuine signals.
References and Sources
External Research
- Sprout Social. (2025). Crisis Management Report: Brand Response Timing and Outcomes. sproutsocial.com/insights
- Institute for Public Relations. (2024). Crisis Response Timing and Sentiment Amplification Study. instituteforpr.org
- Cision. (2025). State of the Media Report: Incident-to-Coverage Timelines. cision.com/resources
- BrightLocal. (2025). Local Consumer Review Survey. brightlocal.com/research/local-consumer-review-survey
- PwC. (2024). Global Crisis Survey: Cost of Brand Crises for Mid-Market Companies. pwc.com/gx/en/issues/crisis-solutions.html
- American Marketing Association. Journal of Marketing: Brand Reputation and Revenue Impact. ama.org/journal-of-marketing
Internal Resources
- Eclincher Enterprise Pricing
- Advanced Brand Monitoring Platform
- Unified Social Inbox & Engagement
- AI-Powered Social Management Platform
- Predictive Sentiment Analytics Guide
- Unified Inbox ROI for 100+ Franchises
- Brand Monitoring in 2026: Automating Sentiment Detection at Scale
- Brand Monitoring in 2026: Beyond Social Listening
- Social Listening in 2026: Turning Conversations into Customer Intelligence
- 10 Best Social Media Monitoring Tools (2026 Guide)





